CDS Incredible Alumni: Jungkyu (JP) Park

Data science is a rapidly growing area of study. Yet many people are still left asking, “What actually is a data scientist?” If there were a simple answer, data science wouldn’t be all the rage it is now. What makes data science so unique, among other things, is the application of the knowledge and skills it takes to be a data scientist to a vast, interdisciplinary array of studies and professions.
Data is everywhere, and data scientists are following. CDS provides students with tools and networks to set them up for success in whichever industry they enter. But don’t take our word for it… Allow us to introduce one of NYU Center for Data Science’s Incredible Alumni: Jungkyu (JP) Park!
JP graduated from the CDS Masters in Data Science program in 2019 and is currently pursuing a PhD in Biomedical Imaging & Technology at NYU School of Medicine. We talked to JP about his experience at CDS and about his recent participation (and team win) in the DBTex Challenge for the detection of biopsy-proven breast lesions on digital breast tomosynthesis (DBT) images. The challenge was jointly organized by the American Association of Physicists in Medicine, the International Society for Optics and Photonics, the National Cancer Institute, and the Duke Center for Artificial Intelligence in Radiology.
CL: Can you tell me what drew you to data science academically, and eventually what brought you to CDS?
JP: I wanted to study data science so that I can help people focus their energy on more interesting problems in their lives.
I was a computer science major in my undergrad, and was fascinated by how much productivity we can achieve by automating mundane tasks in our lives. For example, I once built a web app which helped students worry less about enrolling in classes and spend more time studying for their finals.
However, there were limitations in what kind of tasks I can write programs to automate. When I took machine learning and deep learning courses at my alma mater, I started to understand how these technologies can enable automating a lot more tasks than previously thought feasible. I wanted to learn more about these techniques so that I can help people spend their time doing things that matter more to them.
I chose NYU CDS because I thought this program provides one of the best opportunities to dive deep into deep learning. It had a strong faculty like professor Kyunghyun Cho and professor Yann LeCun, and had a flexible curriculum which let me take all the deep learning courses I wanted to take.
CL: What was your experience at CDS like?
I had incredible opportunities at CDS.
First of all, I worked in a lab with smart fellow students like Jason Phang, Nan Wu and Artie Shen and competent advisors like professor Krzysztof Geras, professor Linda Moy, and professor Kyunghyun Cho. Not only I got to work on a number of publications which could potentially bring real-world clinical values, but also the discussions and model-building experiences helped me grow a lot of skills which I have today. Secondly, I took a set of most enlightening courses. For example, A course called “Optimization-based Data Analysis” by professor Carlos Fernandez-Granda broadened and refined my understanding of working with image data in various representations like frequency space and Wavelet space, which is especially useful when working with medical images. In addition, the “Natural Language Understanding” course by professor Sam Bowman gave me an opportunity to lead a project on a novel scientific question with other fellow students, which was chosen as one of the four exemplary projects in 2019. Lastly, I was fortunate to be a part of such an engaging community of fellow students via the shared spaces, the seminars and other social and professional events organized by the friendly staff like Katheryn and Loraine.
CL: You’re currently working on a PhD at NYU’s School of Medicine, could you tell us what inspired you to study at the School of Medicine? Does your current research still interact with Data science?
My work is at the intersection of medical imaging and AI, so all of my data science skills are valuable in my current studies. My research projects involve building computer vision AI systems for medical images in order to eventually bring clinical value to the radiologists. The tasks I perform include data collection, data cleaning, data engineering, model training and processing the model outputs, all of which are important data science skills.
I chose to pursue a PhD at NYU’s school of medicine so that I can continue to make positive contributions towards finding and solving cancer with the expertise I already built during my time at CDS. I was fortunate enough to continue my work with the same group of amazing fellow students and advisors.
CL: Recently you were on a team of researchers who won an international challenge to use AI to detect breast cancer in DBT images. Could you tell me more how you contributed to this project?
JP: For this project, I performed data collection, data cleaning, data engineering, model training and processing the model outputs. So this is a concrete example of the previous question.
For data collection and cleaning, I imported the medical images as well as the annotations from the radiologists. I cleaned the 2D and 3D mammogram data so that we reject irrelevant scans. I assigned DBT annotations to the radiologists and collected the completed segmentations. And then I cleaned the segmentations so that we can suppress artifacts created by the annotation software and extract appropriate bounding boxes for the lesions.
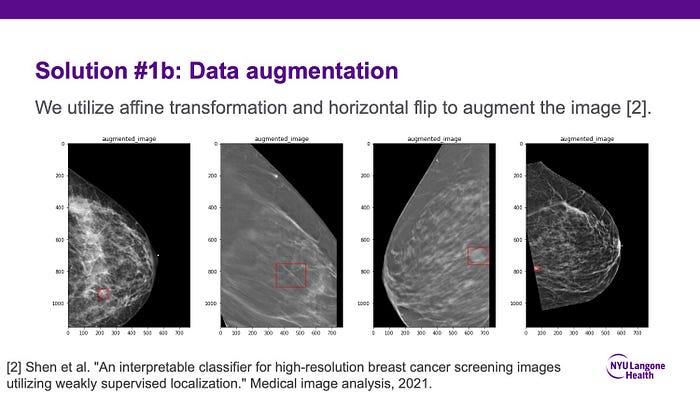
For data engineering, I built a data loading pipeline which can efficiently load the slices from the DBT volumes and the corresponding annotations. This involves cropping the most important regions of the images and augmenting both the images and the corresponding labels the same way.

For model training, I trained various EfficientDet architectures using the data I imported. I tuned hyperparameters such as the learning rate, model complexity, input size, and anchor configurations.
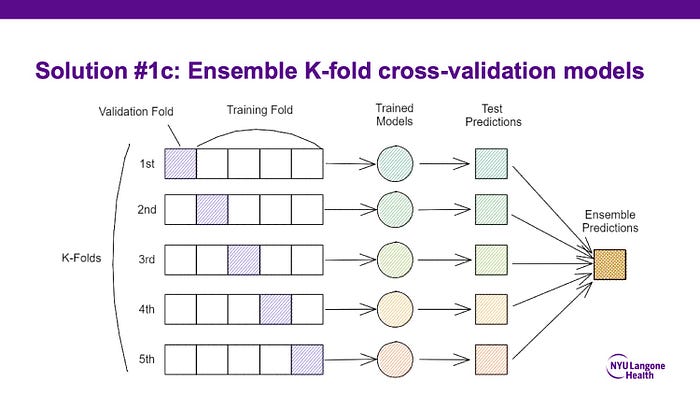
For processing the model outputs, I wrote this novel algorithm that I call “max-slice-selection” to handle the ambiguity of DBT data. The ambiguity of DBT data is that the lesions are visible on more slices than it is present, due to the limited angles used in the volume acquisition. I addressed this ambiguity by aggregating the model outputs to select the center slices of the lesions with this algorithm. I also experimented with different ways of removing duplicate boxes for the same lesion. Lastly, I ensemble the outputs from numerous models trained on differently perturbed datasets. This is done so that we can get a set of box predictions which a lot of models agree upon, and disregard other boxes which only one of the models regard as important.

